
QC Rerun Time 2025 #44

It's hard to believe the first Cubetown visit was like 800 friggin' comics ago, holy crap. Time does weird things when you draw a comic every day for 20-odd years. As I recall, at this point I was still trying to figure out if QC would switch solely to focus on Marten and Claire's Cubetown adventures, or if I'd split the focus between Cubetown and Northampton. I ended up doing the latter, which I think was the right choice. Too many fun characters to just leave behind like that! And of course then I immediately added like four new ones, and then Anh basically took over the comic for a year. Is Sam still going through her goth phase? IS it just a phase? ONLY ONE WAY TO FIND OUT (I will do whatever seems funniest at the time)
QC Rerun Time 2025 #3

A Bembo comic! Man I love these. IIRC, the whole idea for Bembo started off on twitter when I went on a bit of a "dumb barbarian but not in the way you'd expect" style of shitposting spree. Then later that year I needed some filler comics for the week between xmas and new year's so I decided to turn some of those posts into actual comics. And then it became a semi-regular thing! They're very fun and I hope to do more in the future. Bembo is obviously heavily indebted to Oglaf, a comic I adore. Go read Oglaf, unless you don't like cartoons with tits and wieners in them I guess.

Every time I see one of these old comics I think "man, remember when QC was about indie rock lol." Also remember when I used to make jokes about the size of Faye's ass but didn't really know how to draw thicker ladies yet so she pretty much looked like every other character, lol.
The Equational Theories Project: Advancing Collaborative Mathematical Research at Scale
Matthew Bolan, Joachim Breitner, Jose Brox, Nicholas Carlini, Mario Carneiro, Floris van Doorn, Martin Dvorak, Andrés Goens, Aaron Hill, Harald Husum, Hernán Ibarra Mejia, Zoltan Kocsis, Bruno Le Floch, Amir Livne Bar-on, Lorenzo Luccioli, Douglas McNeil, Alex Meiburg, Pietro Monticone, Pace P. Nielsen, Emmanuel Osalotioman Osazuwa, Giovanni Paolini, Marco Petracci, Bernhard Reinke, David Renshaw, Marcus Rossel, Cody Roux, Jérémy Scanvic, Shreyas Srinivas, Anand Rao Tadipatri, Vlad Tsyrklevich, Fernando Vaquerizo-Villar, Daniel Weber, Fan Zheng, and I have just uploaded to the arXiv our preprint The Equational Theories Project: Advancing Collaborative Mathematical Research at Scale. This is the final report for the Equational Theories Project, which was proposed in this blog post and also showcased in this subsequent blog post. The aim of this project was to see whether one could collaboratively achieve a large-scale systematic exploration of a mathematical space, which in this case was the implication graph between 4694 equational laws of magmas. A magma is a set 

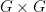
-
(Trivial law):
-
(Singleton law):
-
(Commutative law):
-
(Central groupoid law):
-
(Associative law):

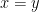



 ; one can explore them in our “Equation Explorer” tool.
; one can explore them in our “Equation Explorer” tool.
The aim of the project was to work out which of these laws imply which others. For instance, all laws imply the trivial law 
After a rather hectic setup process (documented in this personal log), progress came in various waves. Initially, huge swathes of implications could be resolved first by very simple-minded techniques, such as brute-force searching all small finite magmas to refute implications; then, automated theorem provers such as Vampire or Mace4 / Prover9 were deployed to handle a large fraction of the remainder. A few equations had existing literature that allowed for many implications involving them to be determined. This left a core of just under a thousand implications that did not fall to any of the “cheap” methods, and which occupied the bulk of the efforts of the project. As it turns out, all of the remaining implications were negative; the difficulty was to construct explicit magmas that obeyed one law but not another. To do this, we discovered a number of general constructions of magmas that were effective at this task. For instance:
- Linear models, in which the carrier
for some coefficients
, turned out to resolve many cases.
- We discovered a new invariant of an equational law, which we call the “twisting semigroup” of that law, which also allowed us to construct further examples of magmas that obeyed one law
but not another
, by starting with a base magma
that obeyed both laws, taking a Cartesian power
of that magma, and then “twisting” the magma operation by certain permutations of
designed to preserve
- We developed a theory of “abelian magma extensions”, similar to the notion of an abelian extension of a group, which allowed us to flexibly build new magmas out of old ones in a manner controlled by a certain “magma cohomology group
” which were tractable to compute, and again gave ways to construct magmas that obeyed one law
- Greedy methods, in which one fills out an infinite multiplication table in a greedy manner (somewhat akin to naively solving a Sudoku puzzle), subject to some rules designed to avoid collisions and maintain a law
- Smarter ways to utilize automated theorem provers, such as strategically adding in additional axioms to the magma to help narrow the search space, were developed over the course of the project.
Even after applying all these general techniques, though, there were about a dozen particularly difficult implications that resisted even these more powerful methods. Several ad hoc constructions were needed in order to understand the behavior of magmas obeying such equations as E854, E906, E1323, E1516, and E1729, with the latter taking months of effort to finally solve and then formalize.
A variety of GUI interfaces were also developed to facilitate the collaboration (most notably the Equation Explorer tool mentioned above), and several side projects were also created within the project, such as the exploration of the implication graph when the magma was also restricted to be finite. In this case, we resolved all of the
Problem 1 Does the law(E677) imply the law
(E255) for finite magmas?
See this blueprint page for some partial results on this problem, which we were unable to resolve even after months of effort.
Interestingly, modern AI tools did not play a major role in this project (but it was largely completed in 2024, before the most recent advanced models became available); while they could resolve many implications, the older “good old-fashioned AI” of automated theorem provers were far cheaper to run and already handled the overwhelming majority of the implications that the advanced AI tools could. But I could imagine that such tools would play a more prominent role in future similar projects.
Masking in Japan, and Dec 09
So, you know that Japanese people mask more than Americans or Europeans. But how much more? Some numbers from today: ( Read more... )
So, 40-50% generically outside, and 50-75% on trains. On the "masks and exercise" front, I'd note that many bicyclists have been masked, too.
Further, almost but not entirely all of customer-facing employees have been masked. Train, bus drivers, retail shop employees, the few waiters I've seen. I'd say at least 80% conservatively, 90% likely, maybe not much higher (it takes few outliers to push a ratio away from extremes.) I think Seki said that waiters often aren't, but I dunno.
Now, is this the New Normal after covid? Not necessarily. Japan has been having a bad flu season, huge spike in cases, and a major strain (coming soon to a school or hospital near you) wasn't in the vaccine this year, so I think the government has been urging people to mask again. Also it's winter-ish and some people here may have noticed "masks are like a scarf but better."
( Read more... )
The story of Erdős problem #1026
Problem 1026 on the Erdős problem web site recently got solved through an interesting combination of existing literature, online collaboration, and AI tools. The purpose of this blog post is to try to tell the story of this collaboration, and also to supply a complete proof.
The original problem of Erdős, posed in 1975, is rather ambiguous. Erdős starts by recalling his famous theorem with Szekeres that says that given a sequence of 

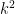




 “.
“.
This problem was added to the Erdős problem site on September 12, 2025, with a note that the problem was rather ambiguous. For any fixed 

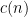
 . Desmond noted that for this formulation one could assume without loss of generality that the were positive, since deleting negative or vanishing does not decrease the left-hand side and does not increase the right-hand side. By a limiting argument one could also allow collisions between the , so long as one interpreted monotonicity in the weak sense.
. Desmond noted that for this formulation one could assume without loss of generality that the were positive, since deleting negative or vanishing does not decrease the left-hand side and does not increase the right-hand side. By a limiting argument one could also allow collisions between the , so long as one interpreted monotonicity in the weak sense.
Though not stated on the web site, one can formulate this problem in game theoretic terms. Suppose that Alice has a stack of 


AI-generated images continue to be problematic for a number of reasons, but here is one such image that somewhat manages at least to convey the idea of the game:

For small 


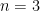




An hour after Desmond’s comment, Stijn Cambie noted (though not in the language I used above) that a similar construction to the one above, in which Alice divides the coins into 






The next day, Stijn computed the first few values of

 , which would also imply that
, which would also imply that  as . (EDIT: as later located by an AI deep research tool, this conjecture was also made in Section 12 of this 1980 article of Steele.) Stijn also described the extremizing sequences for this range of , but did not continue the calculation further (a naive computation would take runtime exponential in , due to the large number of possible subsequences to consider).
as . (EDIT: as later located by an AI deep research tool, this conjecture was also made in Section 12 of this 1980 article of Steele.) Stijn also described the extremizing sequences for this range of , but did not continue the calculation further (a naive computation would take runtime exponential in , due to the large number of possible subsequences to consider).
The problem then lay dormant for almost two months, until December 7, 2025, in which Boris Alexeev, as part of a systematic sweep of the Erdős problems using the AI tool Aristotle, was able to get this tool to autonomously solve this conjecture
This was one further addition to a recent sequence of examples where an Erdős problem had been automatically solved in one fashion or another by an AI tool. Like the previous cases, the proof turned out to not be particularly novel. Within an hour, Koishi Chan gave an alternate proof deriving the required bound 




 ‘s, sending
‘s, sending  , and applying Cauchy-Schwarz, one obtains (in fact the argument gives
, and applying Cauchy-Schwarz, one obtains (in fact the argument gives  for all ).
for all ).
Once this proof was found, it was natural to try to see if it had already appeared in the literature. AI deep research tools have successfully located such prior literature in the past, but in this case they did not succeed, and a more “old-fashioned” Google Scholar job turned up some relevant references: a 2016 paper by Tidor, Wang and Yang contained this precise result, citing an earlier paper of Wagner as inspiration for applying “blowup” to the Erdős-Szekeres theorem.
But the story does not end there! Upon reading the above story the next day, I realized that the problem of estimating 



) were pretty obviously trying to approximate simple rational numbers. There were a variety of ways (including modern AI) to extract the actual rational numbers they were close to, but I searched for a dedicated tool and found this useful little web page of John Cook that did the job: 




 . On posting this, Boris found a clean formulation of the conjecture, namely that
. On posting this, Boris found a clean formulation of the conjecture, namely that 
 and
and  . After a bit of effort, he also produced an explicit upper bound construction:
. After a bit of effort, he also produced an explicit upper bound construction:
Proposition 1 If.
Proof: Consider a sequence 
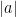


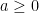




 red elements and at most blue elements, or no red elements and at most blue elements, in either case giving a monotone sum that is bounded by either
red elements and at most blue elements, or no red elements and at most blue elements, in either case giving a monotone sum that is bounded by either 


Here is a figure illustrating the above construction in the

Here is a plot of 

Shortly afterwards, Lawrence Wu clarified the connection between this problem and a square packing problem, which was also due to Erdős (Problem 106). Let 



Proposition 2 For any

Proof: Given 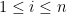
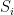
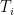







![{[0, S(x_1,\dots,x_n)]^2}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C+S%28x_1%2C%5Cdots%2Cx_n%29%5D%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)


This idea of using packing to prove Erdős-Szekeres type results goes back to a 1959 paper of Seidenberg, although it was a discrete rectangle-packing argument that was not phrased in such an elegantly geometric form. It is possible that Aristotle was “aware” of the Seidenberg argument via its training data, as it had incorporated a version of this argument in its proof.
Here is an illustration of the above argument using the AlphaEvolve-provided example

![\displaystyle 58370, 83179, 117030, 92705, 99080]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+58370%2C+83179%2C+117030%2C+92705%2C+99080%5D&bg=ffffff&fg=000000&s=0&c=20201002)
for 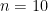

At this point, Lawrence performed another AI deep research search, this time successfully locating a paper from just last year by Baek, Koizumi, and Ueoro, where they show that
Theorem 3 For any

which, when combined with a previous argument of Praton, implies
Theorem 4 For anywith
, one has

This proves the conjecture!
There just remained the issue of putting everything together. I did feed all of the above information into a large language model, which was able to produce a coherent proof of (1) assuming the results of Baek-Koizumi-Ueoro and Praton. Of course, LLM outputs are prone to hallucination, so it would be preferable to formalize that argument in Lean, but this looks quite doable with current tools, and I expect this to be accomplished shortly. But I was also able to reproduce the arguments of Baek-Koizumi-Ueoro and Praton, which I include below for completeness.
Proof: (Proof of Theorem 3, adapted from Baek-Koizumi-Ueoro) We can normalize 



Pick 
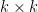

 square, when restricted to this grid, becomes a discrete rectangle
square, when restricted to this grid, becomes a discrete rectangle  for some finite sets
for some finite sets  with
with 




 we conclude that
we conclude that  . Let’s say it is the former, thus
. Let’s say it is the former, thus 
 is at most . But this can be computed to be
is at most . But this can be computed to be  , giving the claim. Similarly if it is the other sum.
, giving the claim. Similarly if it is the other sum.
UPDATE: Actually, the above argument also proves Theorem 4 with only minor modifications. Nevertheless, we give the original derivation of Theorem 4 using the embedding argument of Praton below for sake of completeness.
Proof: (Proof of Theorem 4, adapted from Praton) We write 

![{[0,k]^2}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Ck%5D%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)


 (in particular, larger than ), and consider the three nested squares
(in particular, larger than ), and consider the three nested squares ![\displaystyle [0,k]^2 \subset [0,N]^2 \subset [0,N + |c| \frac{N}{N-\varepsilon}]^2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B0%2Ck%5D%5E2+%5Csubset+%5B0%2CN%5D%5E2+%5Csubset+%5B0%2CN+%2B+%7Cc%7C+%5Cfrac%7BN%7D%7BN-%5Cvarepsilon%7D%5D%5E2.&bg=ffffff&fg=000000&s=0&c=20201002)
![{[0,N]^2 \backslash [0,k]^2}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CN%5D%5E2+%5Cbackslash+%5B0%2Ck%5D%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002) by
by  unit squares. We can similarly pack
unit squares. We can similarly pack ![\displaystyle [0,N + |c| \frac{N}{N-\varepsilon}]^2 \backslash [0,N]^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B0%2CN+%2B+%7Cc%7C+%5Cfrac%7BN%7D%7BN-%5Cvarepsilon%7D%5D%5E2+%5Cbackslash+%5B0%2CN%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle =[0, \frac{N}{N-\varepsilon} (N+|c|-\varepsilon)]^2 \backslash [0, \frac{N}{N-\varepsilon} (N-\varepsilon)]^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D%5B0%2C+%5Cfrac%7BN%7D%7BN-%5Cvarepsilon%7D+%28N%2B%7Cc%7C-%5Cvarepsilon%29%5D%5E2+%5Cbackslash+%5B0%2C+%5Cfrac%7BN%7D%7BN-%5Cvarepsilon%7D+%28N-%5Cvarepsilon%29%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
 squares of sidelength
squares of sidelength  . All in all, this produces
. All in all, this produces 






 , we obtain the claim.
One striking feature of this story for me is how important it was to have a diverse set of people, literature, and tools to attack this problem. To be able to state and prove the precise formula for required multiple observations, including some version of the following:
, we obtain the claim.
One striking feature of this story for me is how important it was to have a diverse set of people, literature, and tools to attack this problem. To be able to state and prove the precise formula for required multiple observations, including some version of the following:
- The sequence can be numerically computed as a sequence of rational numbers.
- When appropriately normalized and arranged, visible patterns in this sequence appear that allow one to conjecture the form of the sequence.
- This problem is a weighted version of the Erdős-Szekeres theorem.
- Among the many proofs of the Erdős-Szekeres theorem is the proof of Seidenberg in 1959, which can be interpreted as a discrete rectangle packing argument.
- This problem can be reinterpreted as a continuous square packing problem, and in fact is closely related to (a generalized axis-parallel form of) Erdős problem 106, which concerns such packings.
- The axis-parallel form of Erdős problem 106 was recently solved by Baek-Koizumi-Ueoro.
- The paper of Praton shows that Erdős Problem 106 implies the generalized version needed for this problem. This implication specializes to the axis-parallel case.
Another key ingredient was the balanced AI policy on the Erdős problem website, which encourages disclosed AI usage while strongly discouraging undisclosed use. To quote from that policy: “Comments prepared with the assistance of AI are permitted, provided (a) this is disclosed, (b) the contents (including mathematics, code, numerical data, and the existence of relevant sources) have been carefully checked and verified by the user themselves without the assistance of AI, and (c) the comment is not unreasonably long.”

Fujisawa 2025-Dec-08
So, yesterday: I worried I'd gotten a germ after all, since I woke up with a slight sore throat and almost-congestion. There was an alternative explanation, "sleeping in a cold dry room", but who knows. I went out for a walk and ended up out for 3 hours, which suggests good health, though I was doing easy pace. ( Read more... )
Understanding Health Insurance: A Health Plan is a Contract [US, healthcare, Patreon]
- Introduction
- A Health Plan is a Contract ⇐ You are here
Health Insurance is a Contract
What we call health insurance is a contract. When you get health insurance, you (or somebody on your behalf) are agreeing to a contract with a health insurance company – a contract where they agree to do certain things for you in exchange for money. So a health insurance plan is a contract between the insurance company and the customer (you).
For simplicity, I will use the term health plan to mean the actual contract – the specific health insurance product – you get from a health insurance company. (It sounds less weird than saying "an insurance" and is shorter to type than "a health insurance plan".)
One of the things this clarifies is that one health insurance company can have a bunch of different contracts (health plans) to sell. This is the same as how you may have more than one internet company that could sell you an internet connection to your home, and each of those internet companies might have several different package deals they offer with different prices and terms. In exactly that way, there are multiple different health insurance companies, and they each can sell multiple different health plans with different prices and terms.
( Read more... [7,130 words] )
This post brought to you by the 220 readers who funded my writing it – thank you all so much! You can see who they are at my Patreon page. If you're not one of them, and would be willing to chip in so I can write more things like this, please do so there.
Please leave comments on the Comment Catcher comment, instead of the main body of the post – unless you are commenting to get a copy of the post sent to you in email through the notification system, then go ahead and comment on it directly. Thanks!
Understanding Health Insurance: Introduction [healthcare, US, Patreon]
Preface: I had hoped to get this out in a more timely manner, but was hindered by technical difficulties with my arms, which have now been resolved. This is a serial about health insurance in the US from the consumer's point of view, of potential use for people still dealing with open enrollment, which we are coming up on the end of imminently. For everyone else dealing with the US health insurance system, such as it is, perhaps it will be useful to you in the future.
Understanding Health Insurance:
Introduction
Health insurance in the US is hard to understand. It just is. If you find it confusing and bewildering, as well as infuriating, it's not just you.
I think that one of the reasons it's hard to understand has to do with how definitions work.
Part of the reason why health insurance is so confusing is all the insurance industry jargon that is used. Unfortunately, there's no way around that jargon. We all are stuck having to learn what all these strange terms mean. So helpful people try to explain that jargon. They try to help by giving definitions.
But definitions are like leaves: you need a trunk and some branches to hang them on, or they just swirl around in bewildering clouds and eventually settle in indecipherable piles.
There are several big ideas that provide the trunk and branches of understanding health insurance. If you have those ideas, the jargon becomes a lot easier to understand, and then insurance itself becomes a lot easier to understand.
So in this series, I am going to explain some of those big ideas, and then use them to explain how health insurance is organized.
This unorthodox introduction to health insurance is for beginners to health insurance in the US, and anyone who still feels like a beginner after bouncing off the bureaucratic nightmare that is our so-called health care system in the US. It's for anyone who is new to being an health insurance shopper in the US, or feels their understanding is uncertain. Maybe you just got your first job and are being asked to pick a health plan from several offered. Maybe you have always had insurance from an employer and are shopping on your state marketplace for the first time. Maybe you have always gotten insurance through your parents and spouse, and had no say in it, but do now. This introduction assumes you are coming in cold, a complete beginner knowing nothing about health insurance or what any of the health insurance industry jargon even is.
Please note! This series is mostly about commercial insurance products: the kinds that you buy with money. Included in that are the kind of health insurance people buy for themselves on the state ACA marketplaces and also the kind of health insurance people get from their employers as a "bene". It may (I am honestly not sure) also include Medicare Advantage plans.
The things this series explains do not necessarily also describe Medicaid or bare Medicare, or Tricare or any other government run insurance program, though if you are on such an insurance plan this may still be helpful to you. Typically government-run plans have fewer moving parts with fewer choices, so fewer jargon terms even matter to them. Similarly, this may be less useful for subsidized plans on the state ACA marketplaces. It depends on the state. Some states do things differently for differently subsidized plans.
But all these different kinds of government-provided health insurance still use some insurance industry jargon for commercial insurance, if only to tell you what they don't have or do. So this post may be useful to you because understanding how insurance typically works may still prove helpful in understanding what the government is up to. Understanding what the assumptions are of regular commercial insurance will hopefully clarify the terms even government plans use to describe themselves. Just realize that if you have a plan the government in some sense is running, things may be different – including maybe very different – for you.
On to the first important idea: Health Insurance is a Contract.
- Introduction
- Health Insurance is a Contract
QC RERUN TIME 2025: The Beginning

lmao that the first comic to pop up when I hit the random button on my site was Faye saying "why's there always gotta be new people"
Looking back at this year, I feel like Anh basically took over the comic? It's wild how it's always the unexpected ones who have the most juice. No offense to Ayo, who is also plenty juicy and I also love writing. But Anh's a couple orders of magnitude more of a mess. But THIS comic is about AYO! Who is a delightful little idiot and I can't wait to do more with. OKAY THANKS I LOVE YOU ALL BYE


time zones and food
Gonna take a while to get used to these time zones differences again. I realized in the shower that as I was preparing to go to bed before Monday, for most of my friends, Sunday morning was just beginning. Also, that's probably why Oglaf hasn't updated yet -- it's Sunday! My webcomics schedule is in confusion. ( Read more... )
New travel series begins
After three years in friendly Very Cheap Rent houses, I'm back to nomadic life. After bouncing around Philly a few times to get things sorted, I'm now in Tokyo, because (a) Japan is cool and (b) old family of friend is old, tick-tock tick-tock. If you want to follow along, well, keep checking in for the travel2025 tag. Some random observations to start: ( Read more... )

WHEEL SMASHING LORD 5-156

Mercenary Soul

They're Just Like Us

just a regular girl

Quantitative correlations and some problems on prime factors of consecutive integers
Joni Teravainen and I have uploaded to the arXiv our paper “Quantitative correlations and some problems on prime factors of consecutive integers“. This paper applies modern analytic number theory tools – most notably, the Maynard sieve and the recent correlation estimates for bounded multiplicative functions of Pilatte – to resolve (either partially or fully) some old problems of Erdős, Strauss, Pomerance, Sárközy, and Hildebrand, mostly regarding the prime counting function

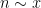 ,
, 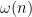 should behave like a gaussian random variable with mean and variance both close to
should behave like a gaussian random variable with mean and variance both close to 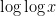 ; but the question of the joint distribution of consecutive values such as
; but the question of the joint distribution of consecutive values such as  is still only partially understood. Aside from some lower order correlations at small primes (arising from such observations as the fact that precisely one of
is still only partially understood. Aside from some lower order correlations at small primes (arising from such observations as the fact that precisely one of 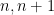 will be divisible by
will be divisible by  ), the expectation is that such consecutive values behave like independent random variables. As an indication of the state of the art, it was recently shown by Charamaras and Richter that any bounded observables
), the expectation is that such consecutive values behave like independent random variables. As an indication of the state of the art, it was recently shown by Charamaras and Richter that any bounded observables  ,
,  will be asymptotically decorrelated in the limit if one performs a logarithmic statistical averaging. Roughly speaking, this confirms the independence heuristic at the scale
will be asymptotically decorrelated in the limit if one performs a logarithmic statistical averaging. Roughly speaking, this confirms the independence heuristic at the scale  of the standard deviation, but does not resolve finer-grained information, such as precisely estimating the probability of the event
of the standard deviation, but does not resolve finer-grained information, such as precisely estimating the probability of the event  .
.
Our first result, answering a question of Erdős, shows that there are infinitely many
 . For
. For  , such a bound is already to be expected (though not completely universal) from the Hardy–Ramanujan law; the main difficulty is thus with the short shifts
, such a bound is already to be expected (though not completely universal) from the Hardy–Ramanujan law; the main difficulty is thus with the short shifts  . If one only had to demonstrate this type of bound for a bounded number of , then this type of result is well within standard sieve theory methods, which can make any bounded number of shifts
. If one only had to demonstrate this type of bound for a bounded number of , then this type of result is well within standard sieve theory methods, which can make any bounded number of shifts  “almost prime” in the sense that
“almost prime” in the sense that  becomes bounded. Thus the problem is that the “sieve dimension”
becomes bounded. Thus the problem is that the “sieve dimension”  grows (slowly) with . When writing about this problem in 1980, Erdős and Graham write “we just know too little about sieves to be able to handle such a question (“we” here means not just us but the collective wisdom (?) of our poor struggling human race)”.
grows (slowly) with . When writing about this problem in 1980, Erdős and Graham write “we just know too little about sieves to be able to handle such a question (“we” here means not just us but the collective wisdom (?) of our poor struggling human race)”.
However, with the advent of the Maynard sieve (also sometimes referred to as the Maynard–Tao sieve), it turns out to be possible to sieve for the conditions 


Our second result, which answers a separate question of Erdős, establishes that the quantity

 , but in view of the Hardy–Ramanujan law, the
, but in view of the Hardy–Ramanujan law, the 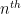 digit of this number is influenced by about
digit of this number is influenced by about  nearby values of , which is too many correlations for current technology to handle. However, it is possible to do some “Gowers norm” type calculations to decouple things to the point where pairwise correlation information is sufficient. To see this, suppose for contradiction that this number was a rational
nearby values of , which is too many correlations for current technology to handle. However, it is possible to do some “Gowers norm” type calculations to decouple things to the point where pairwise correlation information is sufficient. To see this, suppose for contradiction that this number was a rational 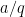 , thus
, thus 
 , we obtain some relations between shifts
, we obtain some relations between shifts  :
:  , one then also gets similar relations on arithmetic progressions, for many and
, one then also gets similar relations on arithmetic progressions, for many and  :
:  and (in analogy to how averages involving arithmetic progressions can be related to Gowers norm-type expressions over cubes), one can eventually arrive eliminate the contribution of small
and (in analogy to how averages involving arithmetic progressions can be related to Gowers norm-type expressions over cubes), one can eventually arrive eliminate the contribution of small  , and arrive at an identity of the form
, and arrive at an identity of the form  , where
, where  is a parameter (we eventually take
is a parameter (we eventually take  ) and
) and  are various shifts that we will not write out explicitly here. This looks like quite a messy expression; however, one can adapt proofs of the Erdős–Kac law and show that, as long as one ignores the contribution of really large prime factors (of order
are various shifts that we will not write out explicitly here. This looks like quite a messy expression; however, one can adapt proofs of the Erdős–Kac law and show that, as long as one ignores the contribution of really large prime factors (of order  , say) to the
, say) to the  , that this sort of sum behaves like a gaussian, and in particular once one can show a suitable local limit theorem, one can contradict (1). The contribution of the large prime factors does cause a problem though, as a naive application of the triangle inequality bounds this contribution by
, that this sort of sum behaves like a gaussian, and in particular once one can show a suitable local limit theorem, one can contradict (1). The contribution of the large prime factors does cause a problem though, as a naive application of the triangle inequality bounds this contribution by  , which is an error that overwhelms the information provided by (1). To resolve this we have to adapt the pairwise correlation estimates of Pilatte mentioned earlier to demonstrate that the these contributions are in fact
, which is an error that overwhelms the information provided by (1). To resolve this we have to adapt the pairwise correlation estimates of Pilatte mentioned earlier to demonstrate that the these contributions are in fact  . Here it is important that the error estimates of Pilatte are quite strong (of order
. Here it is important that the error estimates of Pilatte are quite strong (of order  ); previous correlation estimates of this type (such as those used in this earlier paper with Joni) turn out to be too weak for this argument to close.
); previous correlation estimates of this type (such as those used in this earlier paper with Joni) turn out to be too weak for this argument to close.
Our final result concerns the asymptotic behavior of the density

 and
and  ). Heuristic arguments led Erdős, Pomerance, and Sárközy to conjecture that this quantity was asymptotically
). Heuristic arguments led Erdős, Pomerance, and Sárközy to conjecture that this quantity was asymptotically  . They were able to establish an upper bound of
. They were able to establish an upper bound of  , while Hildebrand obtained a lower bound of
, while Hildebrand obtained a lower bound of  , due to Hildebrand. Here, we obtain the asymptotic for almost all
, due to Hildebrand. Here, we obtain the asymptotic for almost all  (the limitation here is the standard one, which is that the current technology on pairwise correlation estimates either requires logarithmic averaging, or is restricted to almost all scales rather than all scales). Roughly speaking, the idea is to use the circle method to rewrite the above density in terms of expressions
(the limitation here is the standard one, which is that the current technology on pairwise correlation estimates either requires logarithmic averaging, or is restricted to almost all scales rather than all scales). Roughly speaking, the idea is to use the circle method to rewrite the above density in terms of expressions 
 , use the estimates of Pilatte to handle the minor arc , and convert the major arc contribution back into physical space (in which
, use the estimates of Pilatte to handle the minor arc , and convert the major arc contribution back into physical space (in which  and are now permitted to differ by a large amount) and use more traditional sieve theoretic methods to estimate the result.
and are now permitted to differ by a large amount) and use more traditional sieve theoretic methods to estimate the result.